Installation
StatInsight is available for Windows and Linux. Choose your platform below.
Windows
Linux
tar -xzf StatInsight.tar.gzchmod +x StatInsight/StatInsight./StatInsight/StatInsight — or double-click the binary in your file manager.Loading Data
Open a dataset by clicking File → Open File or dragging a file onto the application window. StatInsight automatically detects variable types upon loading.
Supported formats
| Format | Extension | Notes |
|---|---|---|
| CSV | .csv | Delimiter auto-detected (comma, semicolon, pipe, tab) |
| Excel | .xls, .xlsx | Both legacy and modern Excel formats supported |
| RTF | .rtf | Rich Text Format with tabular data |
Variable classification
Each column is automatically classified into one of the following types. You can change the type manually at any time using the variable type selector in the Descriptives tab.
| Type | Description |
|---|---|
| Continuous | Numeric data with many unique values — measurements, weights, lab values |
| Categorical | Limited set of distinct groups — blood type, treatment group, study site |
| Binary | Exactly two distinct values — yes/no, 0/1, male/female |
| Date | Date or time values; common formats auto-recognized |
| Label | High-cardinality text columns (IDs, names) — excluded from statistical analysis |
Saving and reopening projects
Save your entire working session — including loaded data, variable types, and analysis results — as a .stati project file. Use File → Save Project to save, and File → Open Project to resume where you left off.
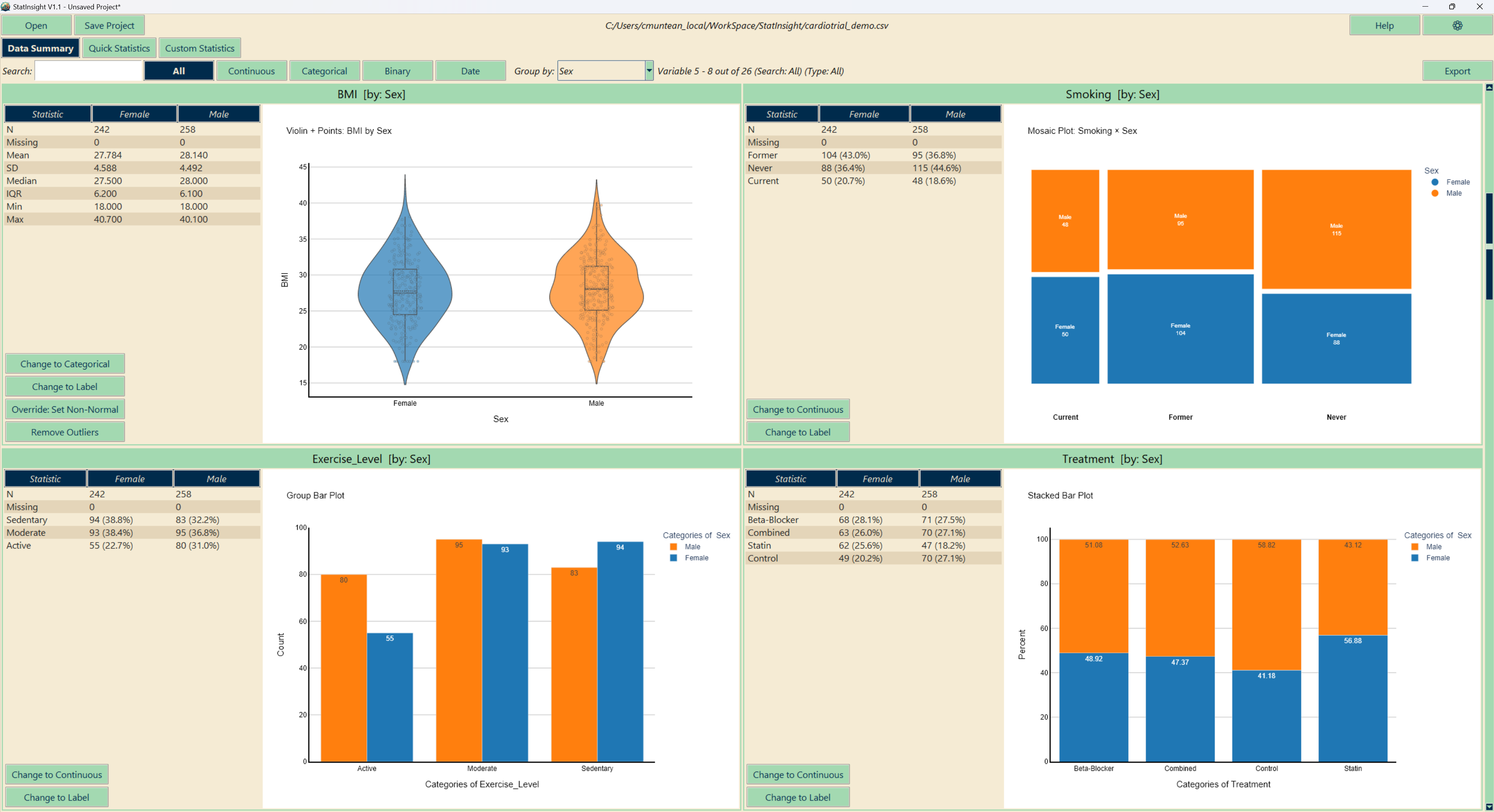
Descriptive Statistics
The Descriptives tab provides an at-a-glance summary of every variable in your dataset. Results update instantly when variable types are changed or outliers are removed.
Continuous variables
For numeric variables with many unique values, StatInsight calculates: mean, standard deviation, median, interquartile range (IQR), minimum, maximum, and sample size. A normality assessment is run automatically (composite of Shapiro-Wilk, Anderson-Darling, skewness, and kurtosis). Each variable is accompanied by an interactive histogram with outlier markers.
Categorical & binary variables
For categorical and binary columns, StatInsight displays frequency counts and percentages for each group, alongside a bar plot. This allows immediate detection of imbalanced groups or data entry errors.
Date variables
Date columns show the earliest and latest values, total span, and a time-area distribution plot to visualize data collection over time — useful for identifying recruitment gaps or data quality issues.
Outlier removal
Outliers are identified using the IQR method: a value is flagged as an outlier if it falls below Q1 − 1.5 × IQR or above Q3 + 1.5 × IQR. An Remove Outliers button is available for each continuous variable, allowing targeted removal without affecting other variables. Removed values are tracked and can be restored.
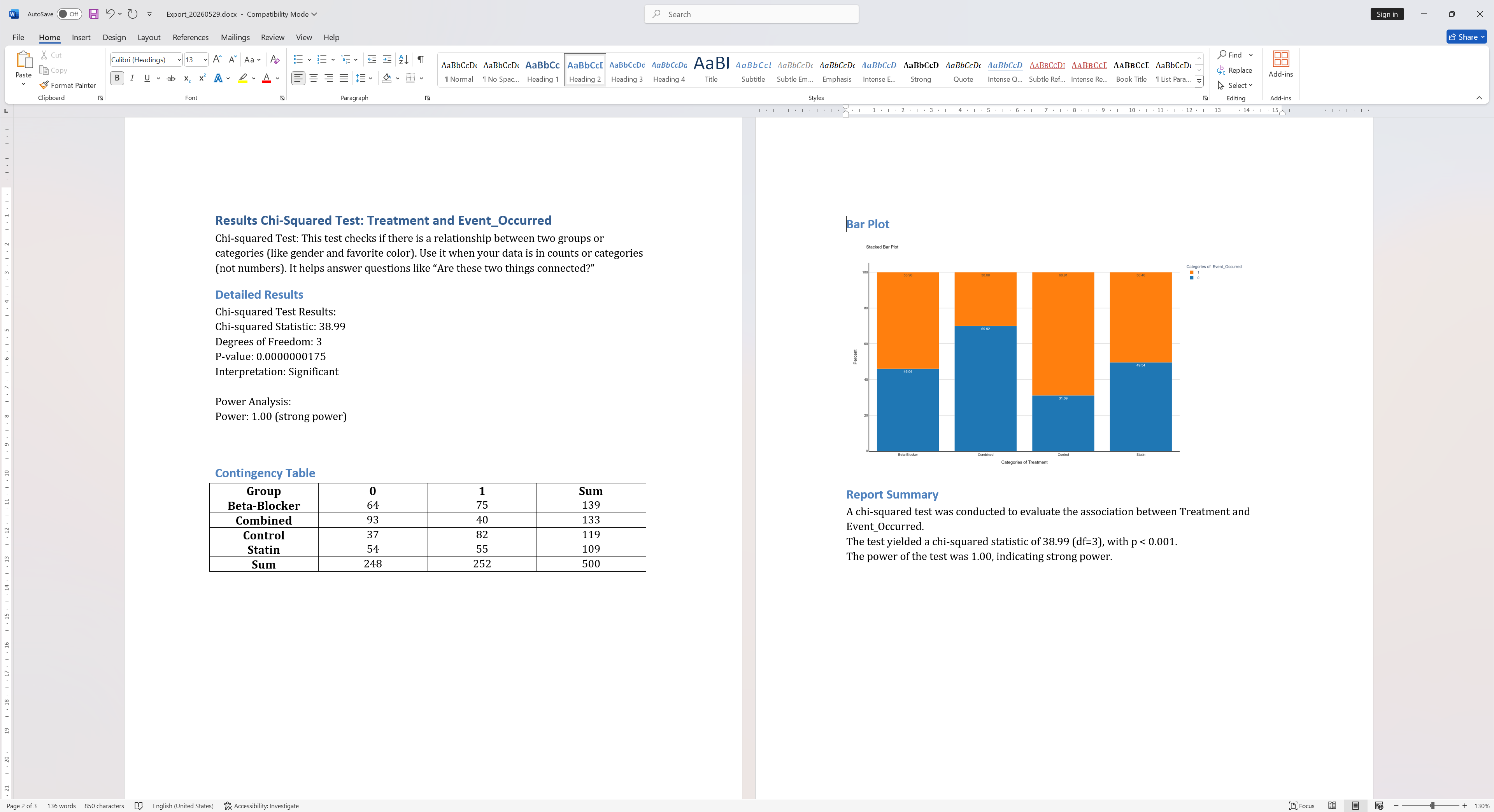
Quick Statistics
Quick Statistics runs all applicable statistical tests on your entire dataset in one click. StatInsight automatically selects the appropriate test for each variable combination based on data type and normality assessment, saving you the effort of choosing tests manually.
What's included in each result
Each result card displays the test name, the variables tested, the key statistics, and a plain-English summary of the finding. Significant results (p < 0.05) are visually highlighted. All results can be filtered and exported — see the Export section for details.
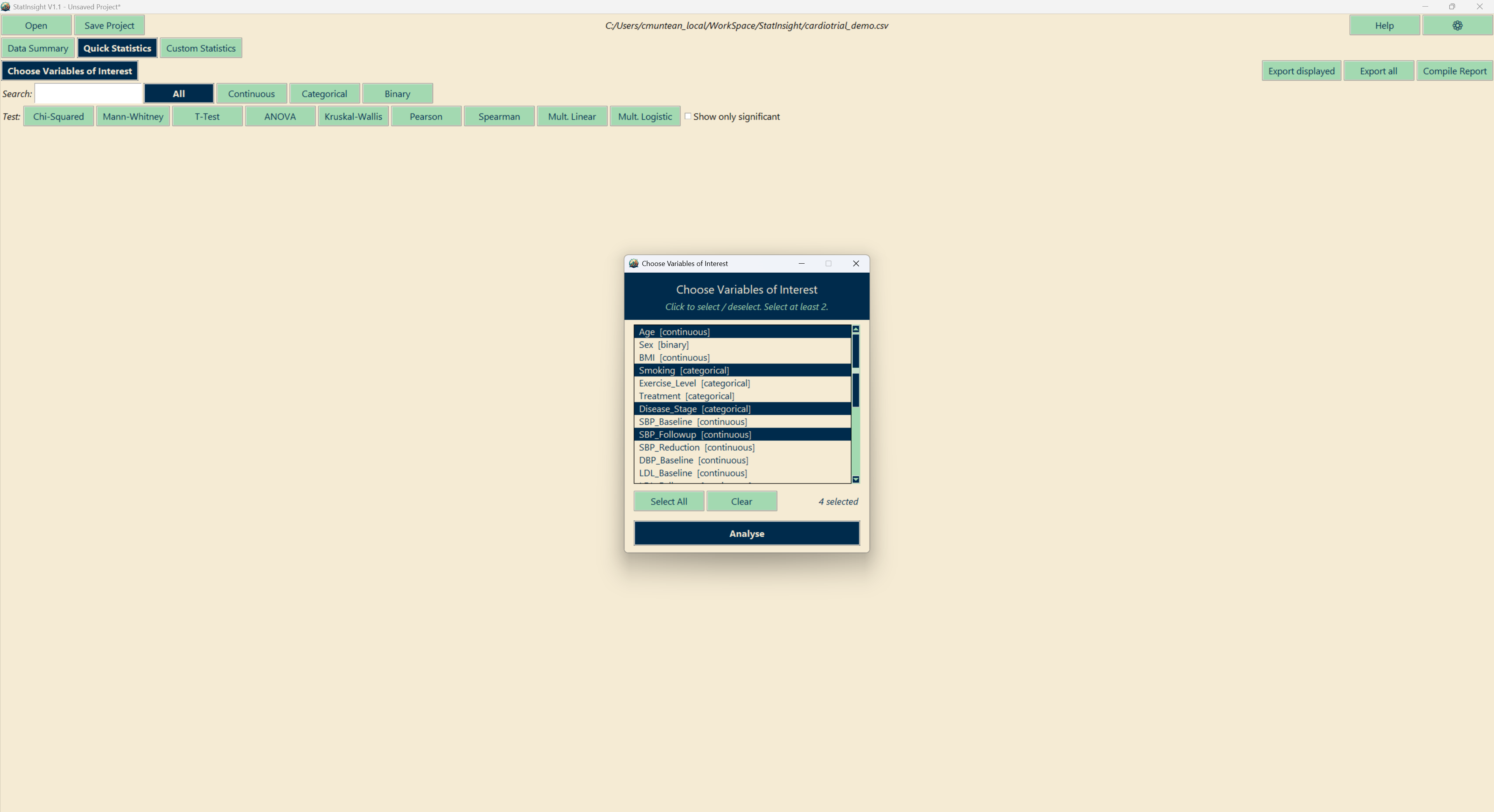
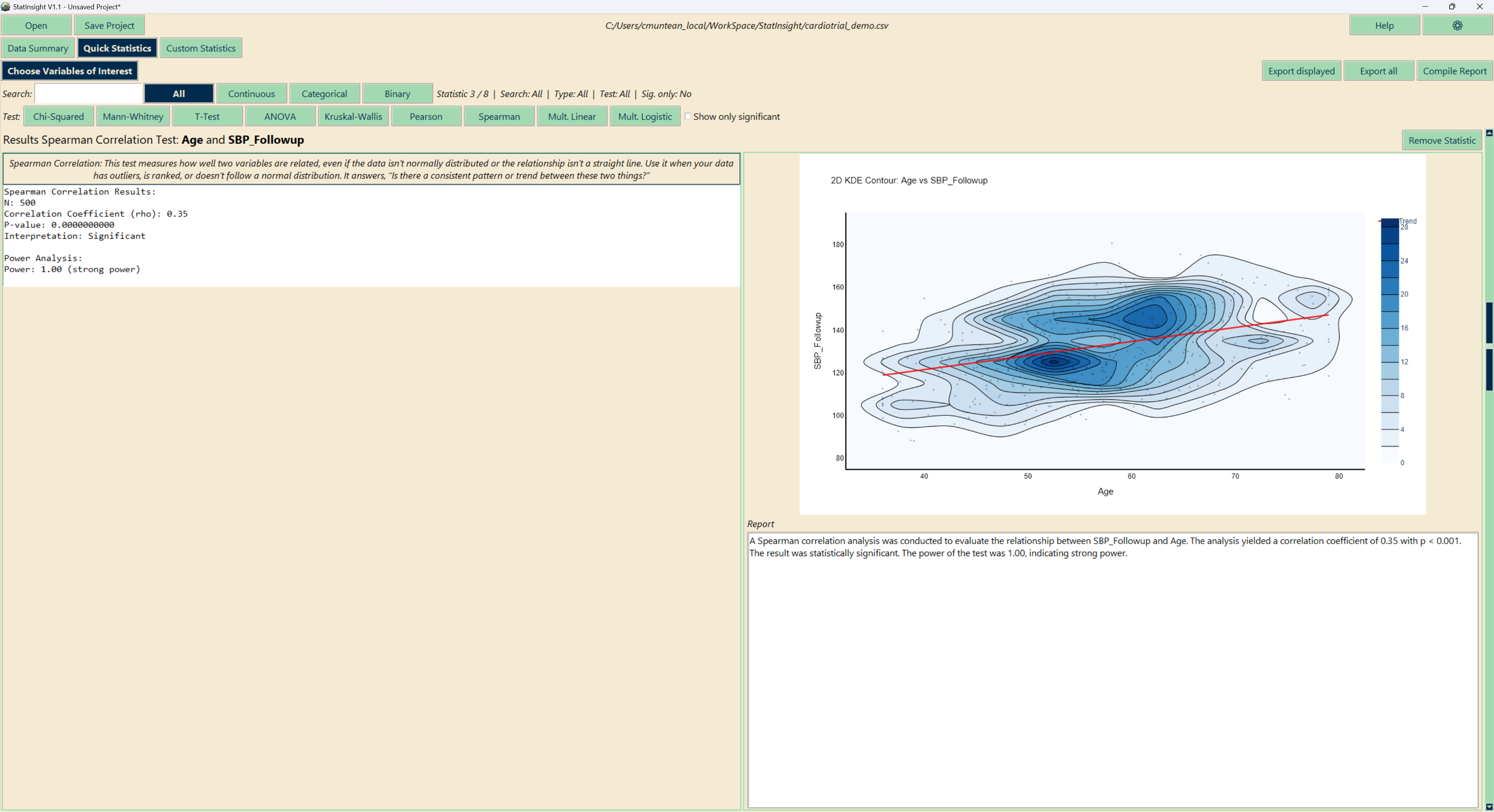
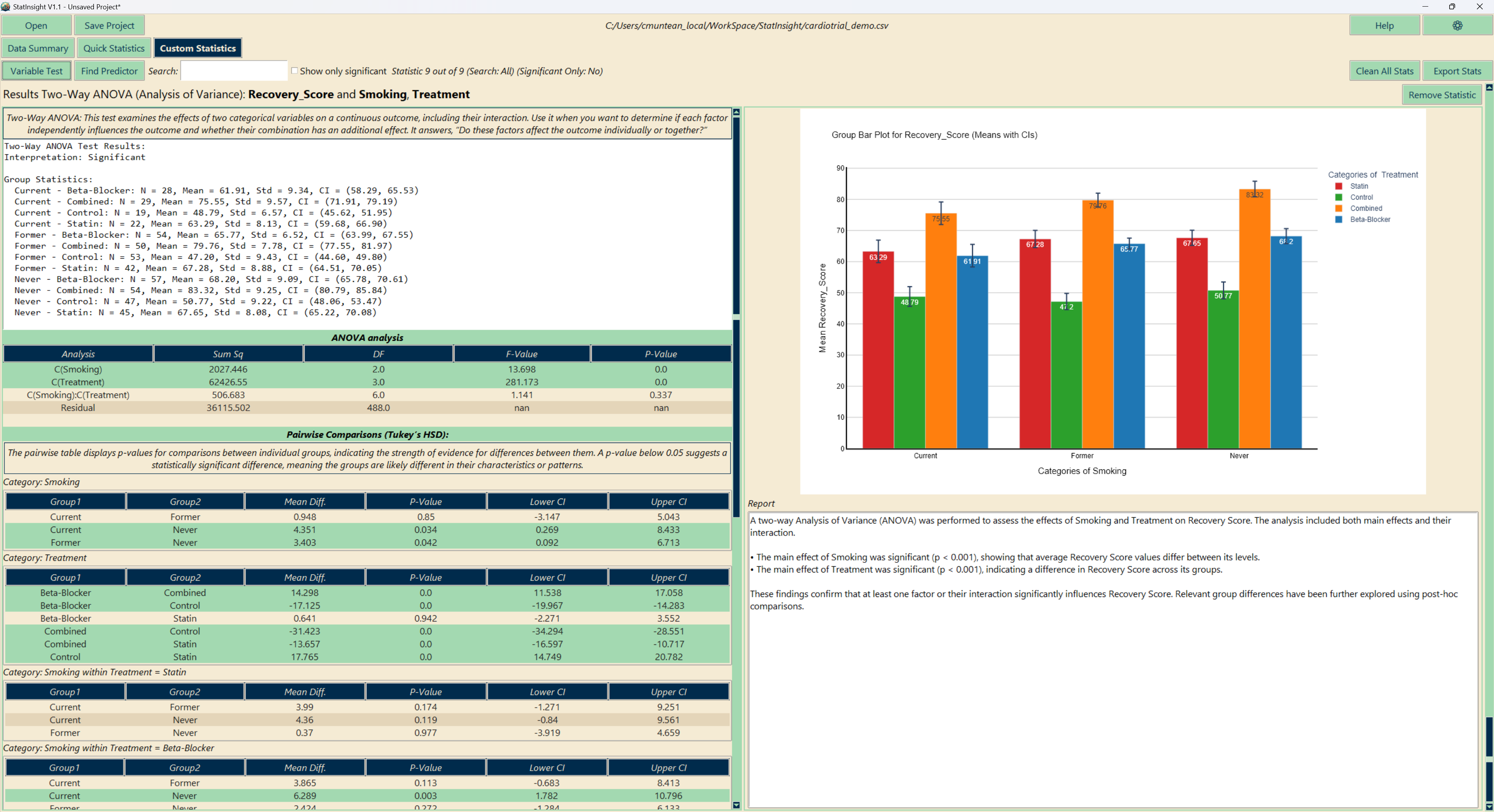
Custom Statistics
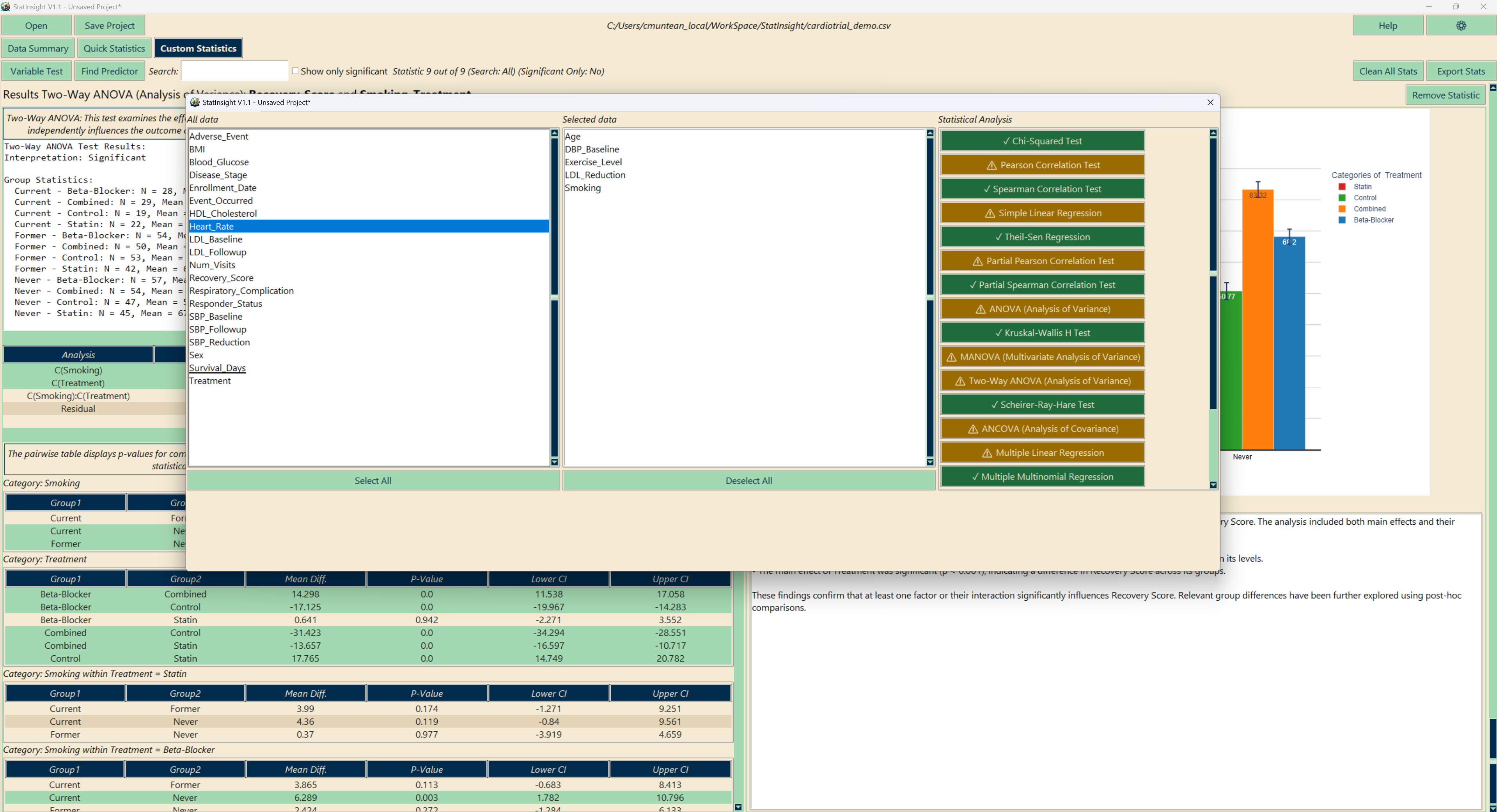
The Custom Statistics tab lets you choose a specific test and configure exactly which variables to compare. This is the right choice when you have a defined hypothesis or need a test not covered by Quick Statistics.
Assumption-aware guidance
Before you run a test, StatInsight evaluates whether your selected data meets the test's assumptions and displays a colour-coded indicator:
Available tests
| Category | Tests |
|---|---|
| Comparison | T-Test, Paired T-Test, Mann-Whitney U, Wilcoxon, ANOVA, Kruskal-Wallis, Repeated Measures ANOVA, Two-Way ANOVA, Friedman, ANCOVA, MANOVA |
| Correlation | Pearson, Spearman, Partial Pearson, Partial Spearman |
| Categorical | Chi-Squared Test |
| Survival | Kaplan-Meier Analysis |
| Regression | Simple Linear, Multiple Linear, Multiple Logistic, Multinomial Logistic |
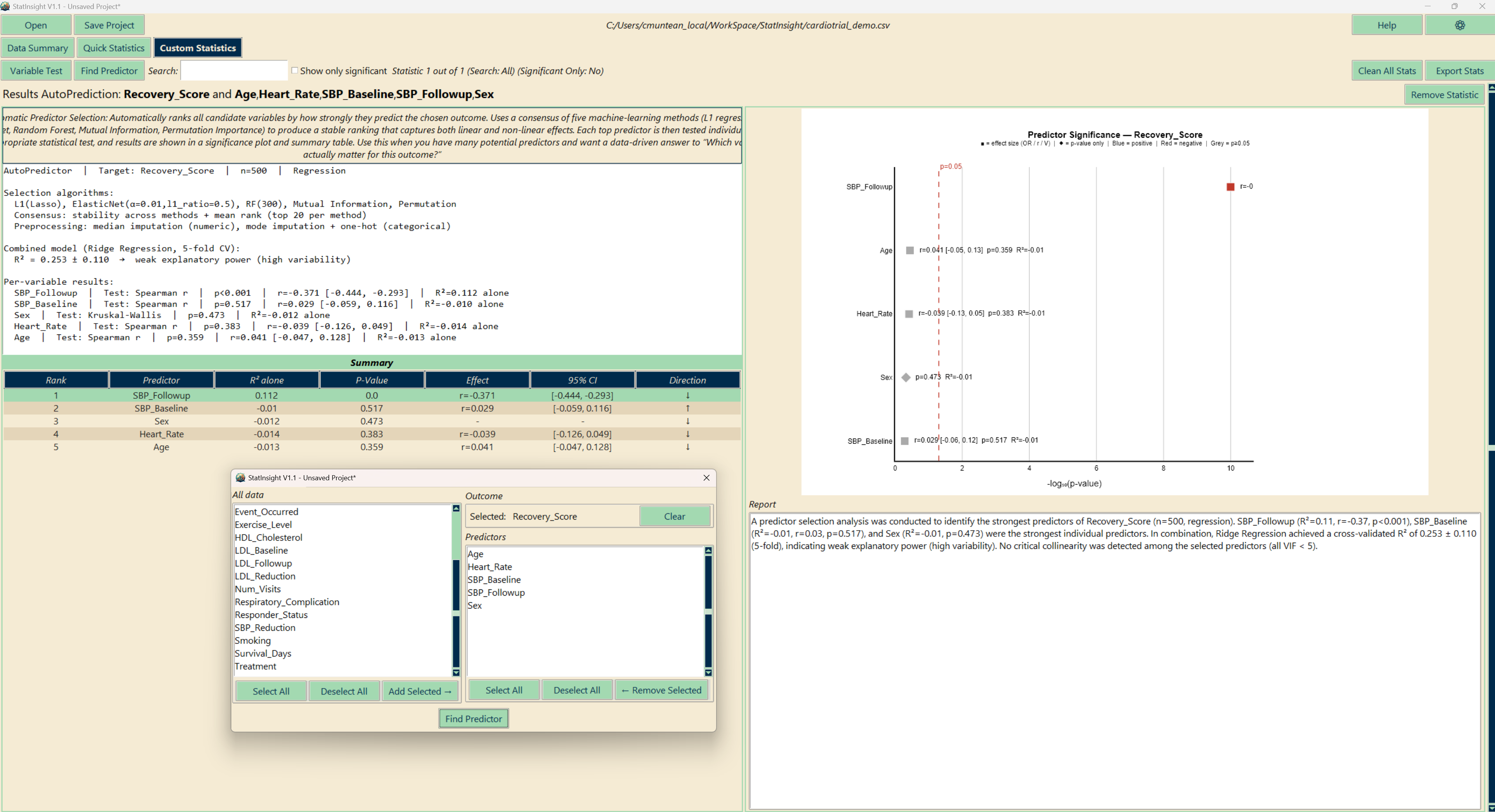
AutoPrediction
AutoPrediction automatically identifies which variables in your dataset are most likely predictors of a chosen outcome variable. Select your outcome and let StatInsight run a battery of machine learning feature selection methods to rank the remaining variables by predictive importance.
Methods used
Results are presented as a ranked list of predictors with a feature importance bar chart, making it straightforward to identify your most influential variables.
Plots
Every result in StatInsight is accompanied by a chart. Plots are generated automatically and can be customized using the built-in plot editor.
Descriptive plots
- Histogram (continuous variables)
- Bar plot (categorical and binary variables)
- Pie chart (categorical variables)
- Box plot (continuous variables)
- Time-area plot (date variables)
Statistical test plots
- Scatter plot with regression trendline (correlation tests)
- Mean bar chart with error bars (T-Test, ANOVA)
- Mean line plot (Paired T-Test, Repeated Measures ANOVA)
- Box plot (Mann-Whitney U, Wilcoxon, Kruskal-Wallis)
- Violin plot (distribution comparisons)
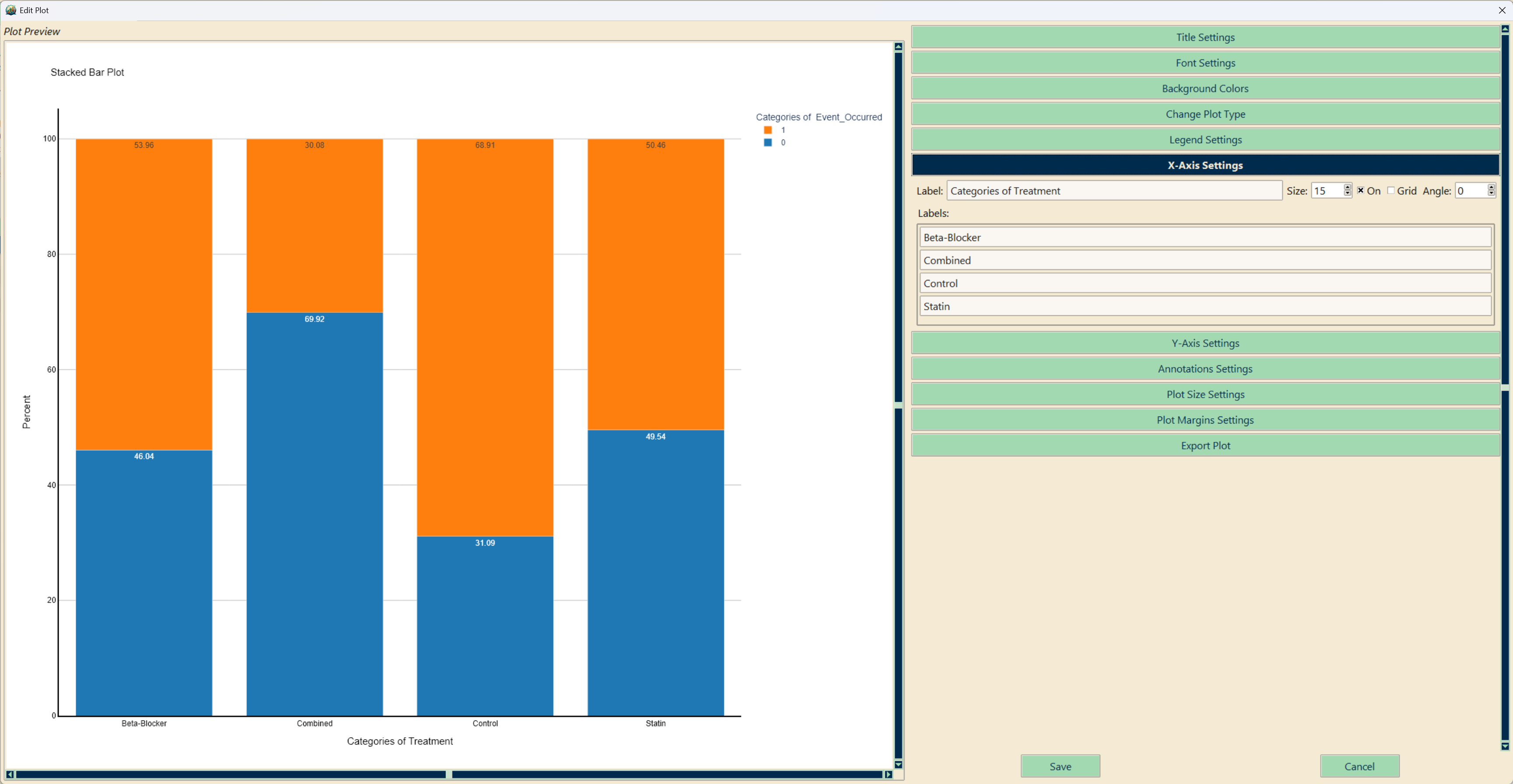
- Stacked bar plot (Chi-Squared test)
- Survival curves with confidence bands (Kaplan-Meier)
- Regression scatter with fit line (linear and logistic regression)
- Feature importance bar chart (AutoPrediction)
Customization
Click the edit icon on any plot to open the Plot Editor. You can modify the chart title, axis labels, color scheme, line styles, and plot dimensions. Changes are applied in real time and are saved with the project file.
Export
StatInsight exports results to Microsoft Word (.docx) format — ready to paste directly into a manuscript or report. Use File → Export to open the export dialog.
What's exported
- Statistical tables with all test metrics (test statistic, degrees of freedom, p-value, effect size)
- Embedded chart images for each result
- Pairwise comparison tables (post-hoc tests)
- Plain-language result interpretation paragraphs
- Regression summary tables with coefficients and confidence intervals
- Kaplan-Meier event tables
Export options
- Export All — exports every result currently loaded in the session.
- Export Filtered — exports only the results currently visible after applying search or filter criteria.